Since fixing the Fjalls system we have a steady stream of data – showing the glacier moving:
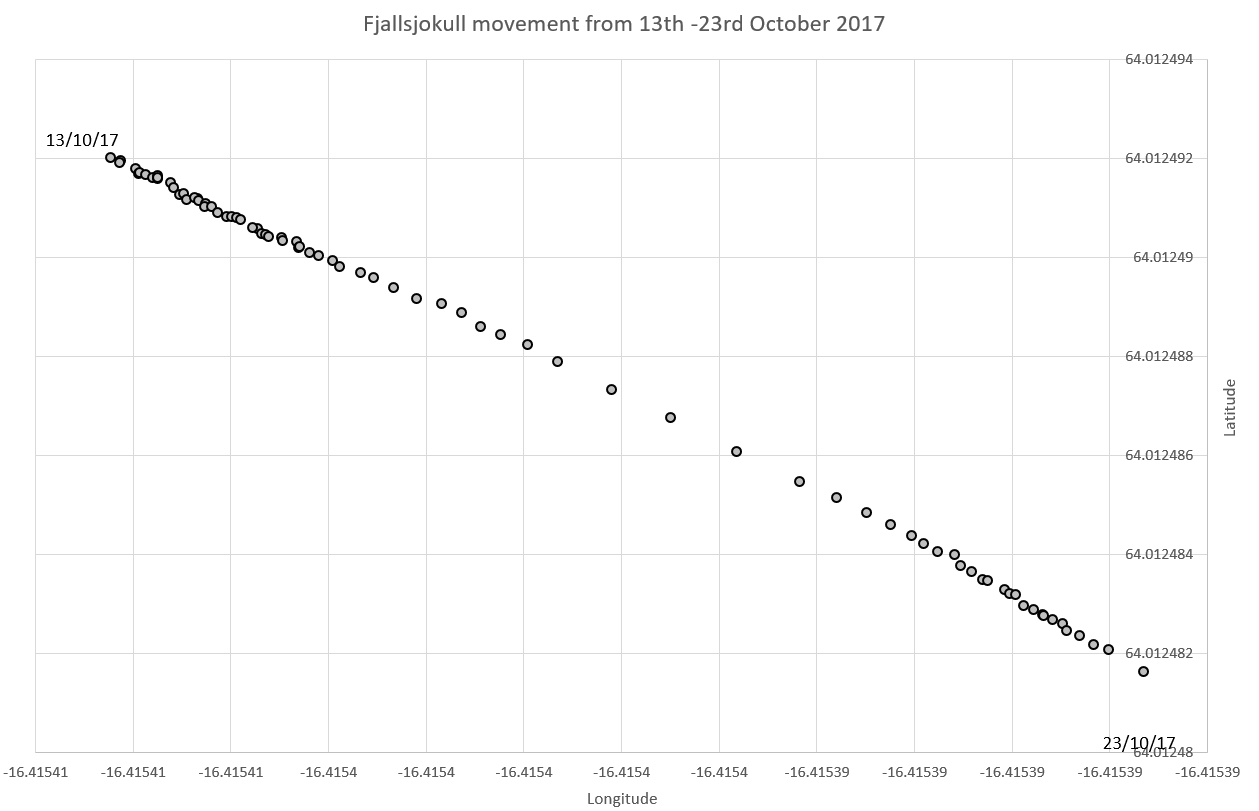
This shows a movement of around 1.5m in just ten days.

Since fixing the Fjalls system we have a steady stream of data – showing the glacier moving:
This shows a movement of around 1.5m in just ten days.
These new dGPS units seem to be accurate to around 2cm as shown in our test. This is for a close baseline (and at the moment doesn’t use GLONASS).
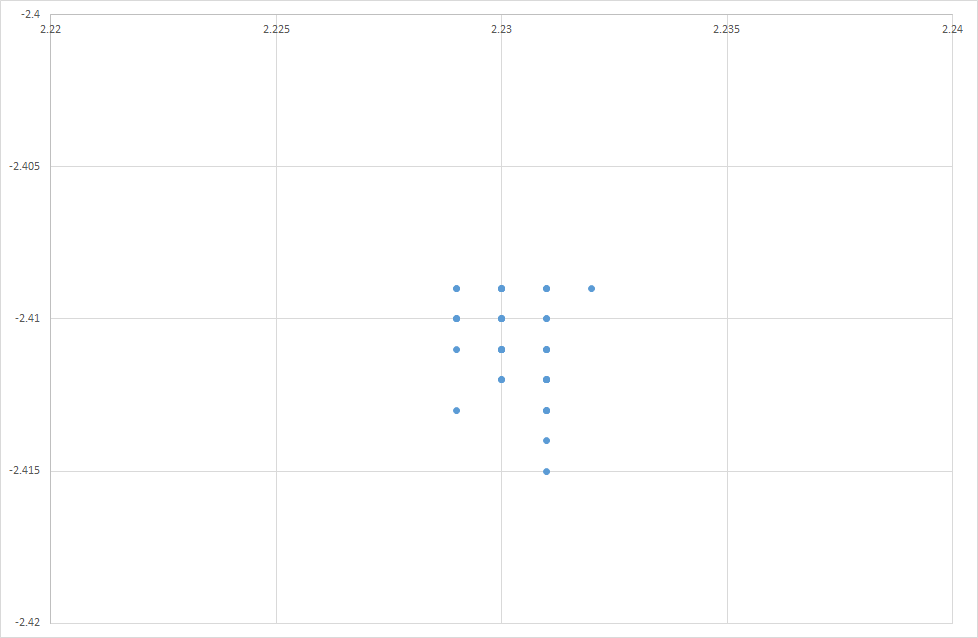
Testing the Piksi Multi from Swift Navigation. North/East relative position of rover – in a 96s test in an open space. The readings are quoted as accurate to 0.023m H 0.037m V.

this shows the glacier-sea front where icebergs calve (Photo: Formula E)

The sea near the glacier – with a variety of icebergs (Photo: Formula E)

Formula E car driving on a glacier in Greenland. This photo shows the icebergs in the sea – like the one we are tracking from here. Photo courtesy Formula E team.

In the center area of this image are the islands off the coast of Greenland where the iceberg we are tracking has been “caught”. You can see there is a whirlpool effect there compared to other areas where bergs pass by. Nasa MODIS images from 18th July – Aug 3rd. excluding cloudy days.
Our GPS data is showing us that the iceberg we are tracking has been drawn into some islands and has stopped moving significantly. The MODIS image data from Nasa was very clear on this day and it is possible to see ice between the islands:

Satellite image of the iceberg being tracked in Greenland – on Aug 29th 2016
We have deployed a Brinno TLC100 camera to monitor the flow in the outlet river from the glacier we work on, footage from this camera can be seen in a previous blog post. However, whilst being simple to set up the output from the camera is not particularly useful for analysis. It saves the images as an avi file, which is great for the amateur timelapse market, not so good for our purposes.
In order to fix this the file was first run through ffmpeg in order to get separate jpeg files for each image. However, this then let to the problem of how to extract the time stamp from the image. Image processing is not area but fortunately the openIMAJ team is based in the same building as us. I went and had a chat to Jon Hare asking if there was anything suitable available off the shelf, unfortunately the software available did not produce good results. So Jon went away and within a few hours he had written a custom piece of software to perform the OCR for us. I then wrapped this in a python script to process a folder and automatically rename the files with the timestamp and add the relevent data to the database.
Once the script had run we had a collection of about 900 images all the the correct timestamp for the file name, and included in the database to enable us to keep track of what times we had images for.
That was the simple part – the hardest part is yet to come – working out river depth from the images we now have.
Thanks to the daily camera image from the base station’s webcam we can see that the snow is starting to settle on the glacier.
")
base station webcam image from oct 31 2012